Seata分布式事务-Raft模式(NEW)全面解析
Seata 是一款开源的分布式事务解决方案,star高达22000+,社区活跃度极高,致力于在微服务架构下提供高性能和简单易用的分布式事务服务.
本篇文章将解析Seata-Server Raft模式的源码,带你领略从调研对比,设计,到具体实现,再到知识沉淀的过程.
分享人:陈健斌(funkye) github id: a364176773
介绍:
同盾科技高级开发工程师 、Seata Committer、Sofa-Jraft & Spring cloud alibaba & Mybatis-Plus (by dynamic-datasource) & Apache-Dubbo & Druid Contributor
Seata-Raft模式作者
注: 特此感谢Seata社区所有参与code review,pr讨论的小伙伴及Sofa-JRaft社区的家纯兄指导.
目录
- raft模式是什么?
- 为什么需要raft模式?
- seata-raft模式是如何设计的.
- 设计上的一些问题探讨
- 总结;
1.Raft模式是什么?
首先我们要明白什么是raft分布式一致性算法,这里直接摘抄sofa-jraft官网的相关介绍:
RAFT 是一种新型易于理解的分布式一致性复制协议,由斯坦福大学的 Diego Ongaro 和 John Ousterhout 提出,作为 RAMCloud 项目中的中心协调组件。Raft 是一种 Leader-Based 的 Multi-Paxos 变种,相比 Paxos、Zab、View Stamped Replication 等协议提供了更完整更清晰的协议描述,并提供了清晰的节点增删描述。 Raft 作为复制状态机,是分布式系统中最核心最基础的组件,提供命令在多个节点之间有序复制和执行,当多个节点初始状态一致的时候,保证节点之间状态一致。
简而言之Seata的Raft模式就是基于Sofa-Jraft组件实现可保证Seata-Server自身的数据一致性和服务高可用.
2.为什么需要raft模式
看完上述的Seata-Raft模式是什么的定义后,是否就有疑问,难道现在Seata-Server就无法保证一致性和高可用了吗?那么我们下面从一致性和高可用来看看目前Seata-Server是如何做的.
2.1.一致性:
在目前Seata的设计中,Server端的作用就是用来保证事务的二阶段被正确的执行,那么我们应该知道被正确的执行的前提条件是什么?
没错,就是事务记录的正确存储和记录,要确保事务记录不丢失,状态不错误下,二阶段驱动所有的Seata-RM时一定是正确的行为,而Seata目前对事务状态和记录是如何存储的?
首先要介绍Seata支持事务存储模式有: file, db, redis 三种模式,根据一致性的排名来db(事务保证)>file(默认异步刷盘)>redis(aof,rdb)
顾名思义:
- file就是Seata自实现的事务存储,默认以异步形式进行存储事务信息到本地磁盘上,为了兼顾性能,默认是异步化,且事务信息存储在内存中,保证内存和磁盘上的一致性,在Seata-Server(以下简称TC)意外宕机时,会在启动时从磁盘读取事务信息并存储到内存中,以便恢复事务上下文继续运转.
- db是Seata抽象出的AbstractTransactionStoreManager另一个实现,背后由数据库如pgsql,mysql,oracle来实现事务存储,这个比较好理解,就是对数据库的增删改查,一致性由数据库的本地事务保证,数据也由数据库的保证落盘.
- redis同上,背后就是利用jedis+lua脚本(部分如竞争锁时)来进行事务的增删改查,数据也是由存储方保证,与db一样在seata中处于计算和存储分离架构设计.
2.2.高可用:
高可用其实简单点理解,就是对集群的容灾,是否在TC宕机后,服务能正常运行,常见的方式就是Provider集群部署(可以说TC就是Seata-Client端的一个Provider),再通过注册中心实时感知TC的上线下,及时的切换到可用的TC.
看起来好像加几台机器,部署即可,但是背后存在了一个问题,如何让多个TC像一个整体一样,即便其中一个宕机后,另一个TC能接手宕机时TC的数据完美善后呢?答案其实很简单,在计算与存储分离的情况下,只要把数据丢到存储方,任意一个TC通过这个公共的存储区域读取即可得到所有TC操作的事务信息,也就保证了高可用的能力.
但是我们也提到了一个前提条件,也就是计算与存储分离下,那么计算与存储一体化设计下为什么不行呢?
这就要说说我们的File实现了,file在一致性那块的描述已经说了,他只是讲数据存储在本地磁盘和TC内存中,这个数据写操作是没有任何同步,也就代表了目前的File模式无法高可用,仅支持单机部署,作为初级的快速入门的简单使用,这也让高性能的file(基于内存)基本被告别生产环境的使用.
3.seata-raft模式是如何设计的
3.1.设计原理
Seata-Raft模式的设计思路是来自于当前无法高可用的file模式的包装,将其的所有增删改操作利用raft算法进行同步,这也就保证了多个TC使用file模式时,数据是一致的,且摒弃了file模式的异步刷盘操作,改为定时刷盘(后面详解)
3.2.流程设计
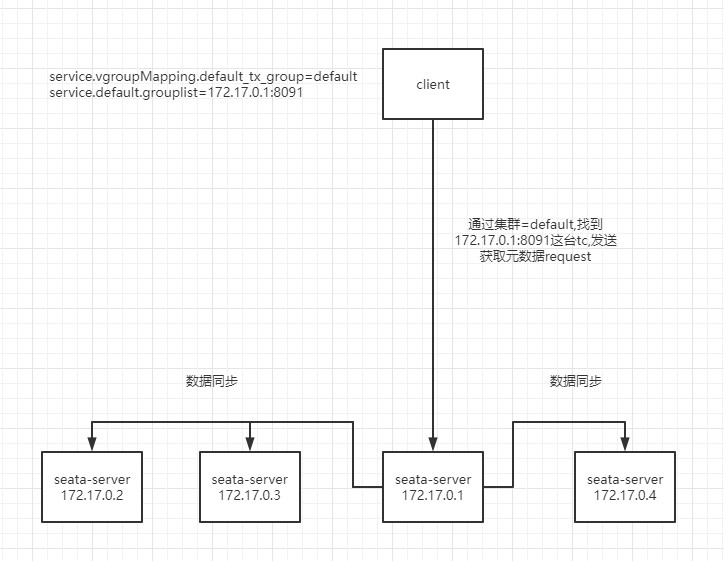
设计示意如上图,client端在启动时,会通过配置中心读取当前client的事务分组,以及相关的raft集群其中一个节点的ip(当然你不嫌麻烦的话可以把整个集群的节点都写上,参考zookeeper那样),通过将获取元数据的request发向172.17.0.1:8091节点后,tc将会把改default raft集群下的元数据返回,即leader&follower&learner

3.2.1.client初始化源码解析
首先client端的代码比较简单,在远程调用处理的抽象类中,将raft模式进行替换掉现有的负载均衡方式具体代码和类如下:
RaftMetadata
1 | public class RaftMetadata { |
TmNettyRemotingClient
1 |
|
RmNettyRemotingClient
1 |
|
AbstractNettyRemotingClient
1 | // 缓存leader地址 |
3.2.2.server端初始化源码解析
首先我们看SessionHolder这个类,此类保存了TC端的所有sessionmanager的实例,并管理其初始化,在初始化后我们就可以来构建raft的相关服务,以下是源码解析
1 | public static void init(String mode) { |
既然我们看到了在RaftServerFactory中进行了初始化,那么接下来就带大家来继续解析
1 | public void init(String host, int port) { |
接着我们看看RaftServer的具体实现类的初始化都做了哪些事RaftServerImpl
1 | private final Logger logger = LoggerFactory.getLogger(getClass()); |
ok,直此TC端的raft初始化相关内容已经解析完毕.
3.2.3.server端raft存储模式源码解析
首先通过上述的server端初始化源码,已经可以初步知晓raft存储模式就是包装了file存储模式,并摒弃他原本的事务存储方式,增加raft的日志和快照存储及数据同步,那么我们现在就来看看相关的类吧
RaftLockManager-Raft的全局锁实现,再老方案中一味的只考虑到follower因与leader执行相同的动作得到相同的结果,故忘记了动作可能存在无意义性,故在新版设计中,将raft的lockmanager直接继承file lock manager即可,并只需要在解锁时进行同步即可
1 | (name = "raft") |
这样lock的实现就很简单了,无需进行同步,而是在添加分支事务时同步分支时一并处理即可,再后续讲到状态机章节会再次提及
而session这块的实现就是将filesessionmanager进行一个继承,使globalsession和branchsession的增删改行为以raft算法进行同步
1 | (name = "raft", scope = Scope.PROTOTYPE) |
1 | public class RaftTaskUtil { |
1 | public class RaftSyncMsgSerializer { |
如上所述,raftsessionmanager做的任务就是把每次的写操作进行同步到follower节点,通过raft一致性协议保证了多节点的数据一致性,那么这个时候我们就应该去了解状态机的设计,因为这才是同步的核心地方
RaftStateMachine-TC的raft状态机类,此处着重讲述seata利用sofa-jraft状态机做了什么,具体可以访问sofa官网
1 | public class RaftStateMachine extends StateMachineAdapter { |
我们来重点看下执行器做了什么,首先看下AddGlobalSessionExecute
1 |
|
AddBranchSessionExecute,此时我们可以解答一下与老版设计对比,为什么不需要同步锁了,因为在seata-server中当分支被添加的时候,也就是走到sessionmanager中的onaddbranch时,只有获取了锁成功的分支才会走到此处,所以当分支被同步的时候,也就意味着锁一定是争抢成功,这样就避免了很多无意义的锁同步行为,将锁同步和分支事务添加合并为一次同步任务即可.
1 |
|
按照顺序,一个正常的事务流程 addglobalsession->addbranchsession->releaseGlobalSessionLock->,updateglobalsession->updatebranchsession(不一定有,成功执行二阶段后会直接删除branch)->branchReleaseLock->removebranchsession->updateglobalsession(更改事务为end状态)->removeglobalsession,所以我们按顺序看响应的执行器
1 | public class UpdateGlobalSessionExecute extends AbstractRaftMsgExecute { |
1 | public class UpdateBranchSessionExecute extends AbstractRaftMsgExecute { |
1 | public class RemoveBranchSessionExecute extends AbstractRaftMsgExecute { |
1 | public class RemoveGlobalSessionExecute extends AbstractRaftMsgExecute { |
1 | public class BranchReleaseLockExecute extends AbstractRaftMsgExecute { |
1 | public class GlobalReleaseLockExecute extends AbstractRaftMsgExecute { |
以上Seata-Server(TC)端的相关涉及源码解读已经完毕,在阅读以上代码后,相信大家已经对client-server两端的实现已经有比较清晰的认知了,接下来我们来看看server与client端在raft下的通信相关设计
3.2.4.Client&Server端通信源码解析
接下来我们可以与client相关的初始化做个连线
AbstractTCInboundHandler类中作为tc接收client请求的处理类,所以获取metadata的相关处理也是写在了此处
1 |
|
AbstractTCInboundHandler-处理RM/TM客户端请求消息
1 |
|
可以看到与原先的rpc设计上区别就是,如果是raft存储模式,那么必须在状态机完全处理完这个请求的所有操作后再做响应,所以大家会看到在createTask的时候利用了completableFuture进行阻塞等待事务相关增删改的结果,这样就可以让client获得响应的时候是一个正确状态,而非异步不确定状态,很多同学不了解raft一致性算法的可能会有疑问,我通过sofa-jraft官网提供的设计图来解释
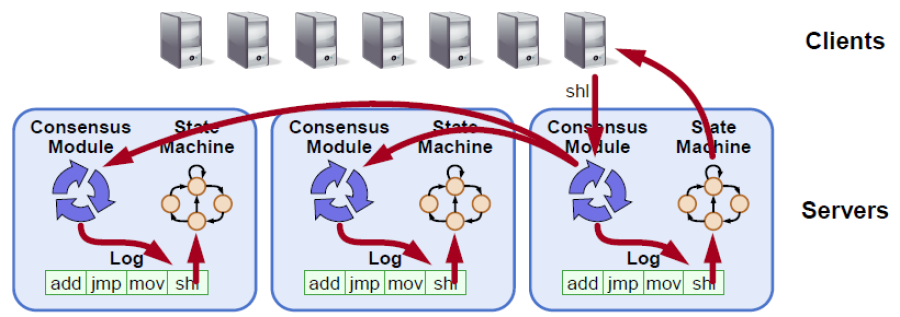
首先我们看到client端的请求通过一致性算法,将操作,比如我们上述所说的添加/修改/删除事务的操作通过日志形式传递,并在超过半数follower应用了该日志后,leader的状态机才会去做处理,如leader是最后才写数据(相对半数follower),而状态机的执行相对client端是异步(状态机是串行,但是跟client请求不是一个线程),也就是对client端的响应必须在写操作都做完了再响应,所以这里的设计利用了状态机是串行有序的,如果server能响应给client,说明先前的增删改操作是同步完成,数据一致的情况,也代表了数据准确落盘(在raft模式下写入内存),那么此时去响应client端是正确行为,如果直接响应,那么由于状态机和业务线程不是同一个,相对业务线程,写操作完全异步化掉了,业务线程响应给client时,未必数据写完了,这个响应的结果可能就有出入.
3.2.5 raft选主解决分布式任务调度解析
DefaultCoordinator#init 该类是异步提交,回滚重试,重试提交,检查事务超时,undolog 防悬挂记录删除的定时任务初始化函数,我们来看下再集成raft之前,是怎么处理的
1 | /** |
可以看到以上的定时任务,就是这么简单的审计,定时线程来跑任务即可,我们试想一下,在db,redis模式中,因为存储是用的外部存储来保证多tc的资源共享,那么在定时任务的时候,没有做任何排他操作,很可能会出现,同一个事物需要提交补偿的时候,多个tc的定时任务同时发动,同时再数据库读出了同一批需要重试提交的事务,进行下发,那么会带来什么问题呢?
没错,就是幂等性问题(XA与AT及SAGA模式无影响,TCC需要业务自己保证幂等),且多个tc对同一批的事务进行处理也是极大的资源浪费,这是很不可取的.Seata在先前本来想打算引入分布式任务调度组件来解决此问题,而Raft的集成顺带也就解决了此问题,我们来看一下raft下定时任务是如何处理的.
1 | /** |
一幕了然,再未来的版本中,TC端预留了对每个模式的分布式锁实现的接口,后续单独的db,redis模式会实现各自的分布式锁机制,使定时任务不再冲突,而raft模式下,对预留的锁接口是如何实现的呢?其实很简单,如果发现当前是leader节点,就等于拿到锁了
我们来看看raft里对相关定时任务的分布式锁是如何做default处理的
1 | (name = "raft") |
然后我们来看一下RaftServerFactory中的isleader又是如何判断,且兼容不用raft进行选举的场景,比如纯db模式
1 | public Boolean isLeader() { |
而如果是db或redis下不用raft又该怎么处理呢?很简单,直接实现相应的acquireLock,不就把default给重写了吗?这就保证了纯db/redis下由对应的store实现分布式锁的设计,而db/redis+raft选举下,直接由leader执行定时任务即可解决集群下冲突的问题.
至此Seata-Server与Sofa-JRfat的结合源码已经解读完毕,接下来我们来讲讲设计上的一些问题并给出个人的理解.
4.设计上的一些问题探讨
1.为什么要同步file模式的数据
答: 首先file不支持高可用的原因就是数据不同步,导致宕机后事务数据无法共享,部分数据可能被脏写,如AT模式需要全局锁来保证隔离性,如果多个tc使用file模式各自为营,那么client端通过LB策略请求的tc截然不同,必定造成数据混乱,从而影响分布式事务的一致性
2.那为什么不直接同步LOCK数据即可?
答: 无法只同步lock数据,其一是一致性问题,如果通过同步lock的话,其余tc在接收到写请求时,lock数据还未同步到位,此时是从何查起呢?不知源头,不知何时同步,不知该不该阻塞等待,所以基本上主流的分布式一致性算法都是由leader来写入数据,因为leader才是真正数据最准确的存在,且也避免了上述所说的不知道什么时候lock数据才同步到位的尴尬局面,所以无法保证分布式事务的隔离性,必须由leader来处理,并不只是同步数据那么简单.
3.那为什么不独立lock到公共存储如db或者redis呢?
答: 未来会支持这种方式,通过lb策略,使begin时路由到的TC地址作为标识,后续的所有rm都会直接请求begin的那台TC,这样事务信息保证了在此raft-group内是一致准确的.这样在tcc xa saga模式下无需全局锁互斥时,可大幅提升吞吐量,而at需要全局锁互斥必定需要一个公共的地方存放锁,在单raft集群模式下直接存储在raft集群中即可,multi-raft下存储在外置存储器上虽然带来了一定吞吐下降,但相对之前的计算与存储完全分离下理论上有可靠的提升.
4.为什么目前由client端主动请求leader节点,而不像zookeeper之类的进行写请求转发呢?
答: 1.性能考虑: 分布式事务的二阶段下,明显带来的就是多次rpc确认事务决议状态,并下发响应结果造成的性能下降,如果直接由server端进行转发,那么其实也存在转发过程中leader的变更,这种由server端转发的方案会带来一定的性能下降,所以目前没有此考虑. 2.中间件职责不同: zookeeper这类的工具并不会像seata那样会有大量的读写请求,即便使用的tps低一些也是能接受.
5.与redis-cluster/sentinel及db模式主备模式比,raft模式的优劣
答:
redis模式对比:
一.cluster跟sentinel一样,存在数据丢失的可能,cluster是一主一备6台redis服务组成,master同步到slave时无法保证强一致性,且cluster适合超大数据量需要数据分片的场景,当前TC的设计在事务结束后就删除,其实是不太适合的.
二.sentinel也是一样无法保证强一致,比如aof的持久化,极大影响redis吞吐,sentinel可以设置让master得到slave写入响应,但是这样一来也就跟raft无太大差距,如raft也需要让follower写入,自身再写,redis又是外部存储多了一次网络io的开销,再吞吐上理论上是比不过raft模式
db模式对比:
一.db模式在seata中目前尚不支持主备切换,首先虽然根据数据库的redolog&binlog二阶段提交来同步到slave,但是说到底master并不会感知slave是否写入了数据,只是关注是否发出了广播,再极限情况下比如master写入了全局锁后宕机,server端对client响应分支注册成功,此时slave接替master后,又来了一个分支进行update操作去争取全局锁,而此时slave还没收到master的全局锁写入广播(可能由于网络问题),所以另一个分支的update操作就被准许,此时前一个事务如果需要回滚会因为后续的update事务没有被全局锁隔离,导致脏写无法回滚的局面,这是不可取的.
二.目前基于db的模式对磁盘和cpu的要求较高,一些用户使用8c16g配置,ssd硬盘可轻松上1200+tps,而使用同等配置下使用机械硬盘可能只有800+左右的tps.究其原因便是seata-server在事务结束后立马就删除造成的数据库频繁的写擦操作,在并发量大的时候,很可能导致大量的页分裂,页合并等行为有严重影响性能的可能性,而raft模式基于对file模式的包装,基于内存的操作,效率理论上远高于db模式,且也能保证数据的一致性.
5.总结
在Seata未来的发展中,性能是至关重要了,我们要对二阶段协议带来的性能下降做尽可能的优化,如存储方面,资源利用率方面,通信方面.这也就代表了我们需要将更多可掌握的拿捏在手,file模式就是一个自实现的事务存储模式,基于此,我们可在自己能力范畴中,以及社区的力量加强对其的优化,把存储性能掌握在自己手中,而外部存储的方案当然也是有好处的,但是对其调优能力因人而异,维护seata组件的相关同学既要维护server端的相关优化指标,也要关注数据库的相关指标,导致有关注点分散,性能问题不好定位的情况.raft模式的到来,代表了类似于redis模式的基于内存的写操作的性能提升,足够的可操控空间,除去了外部的磁盘&网络io开销,达到一个自主可控的阶段.
当然现阶段可能raft模式还不太成熟,未必有上述描述的那般美好,但更因为理论如此,我们应该让事实如此,在此我们欢迎任何对Seata有兴趣的同学加入社区,共同维护,共同进步,一起为Seata分布式事务添砖加瓦!

